"High latency occurs when users wait for responses that could have been reused instantly, leading to increased costs as identical reasoning is paid for multiple times."
"Traditional caching assumes identical inputs produce identical outputs, which fails for natural language, resulting in low hit rates in LLM-backed systems."
"Repeated paraphrased queries can overwhelm a system, causing wasted capacity as LLM throughput is consumed by redundant requests."
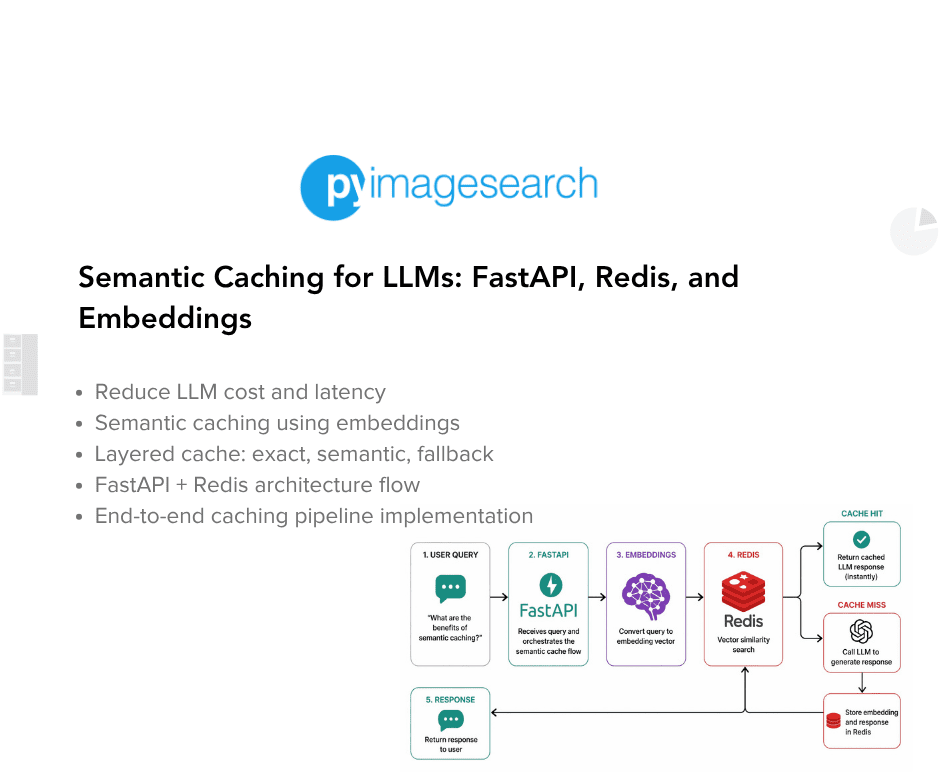
"A semantic cache allows for requests to flow from exact matches to semantic matches, optimizing LLM usage and minimizing unnecessary calls."
A semantic cache for LLM applications can significantly improve efficiency by addressing high latency, increased costs, and wasted capacity. Traditional exact-match caching fails with natural language due to its reliance on identical inputs producing identical outputs. This leads to low hit rates in LLM systems, as similar queries are treated as distinct. By implementing embedding-based similarity search, requests can flow from exact matches to semantic matches, optimizing the use of LLMs and reducing unnecessary invocations.
Read at PyImageSearch
Unable to calculate read time
Collection
[
|
...
]