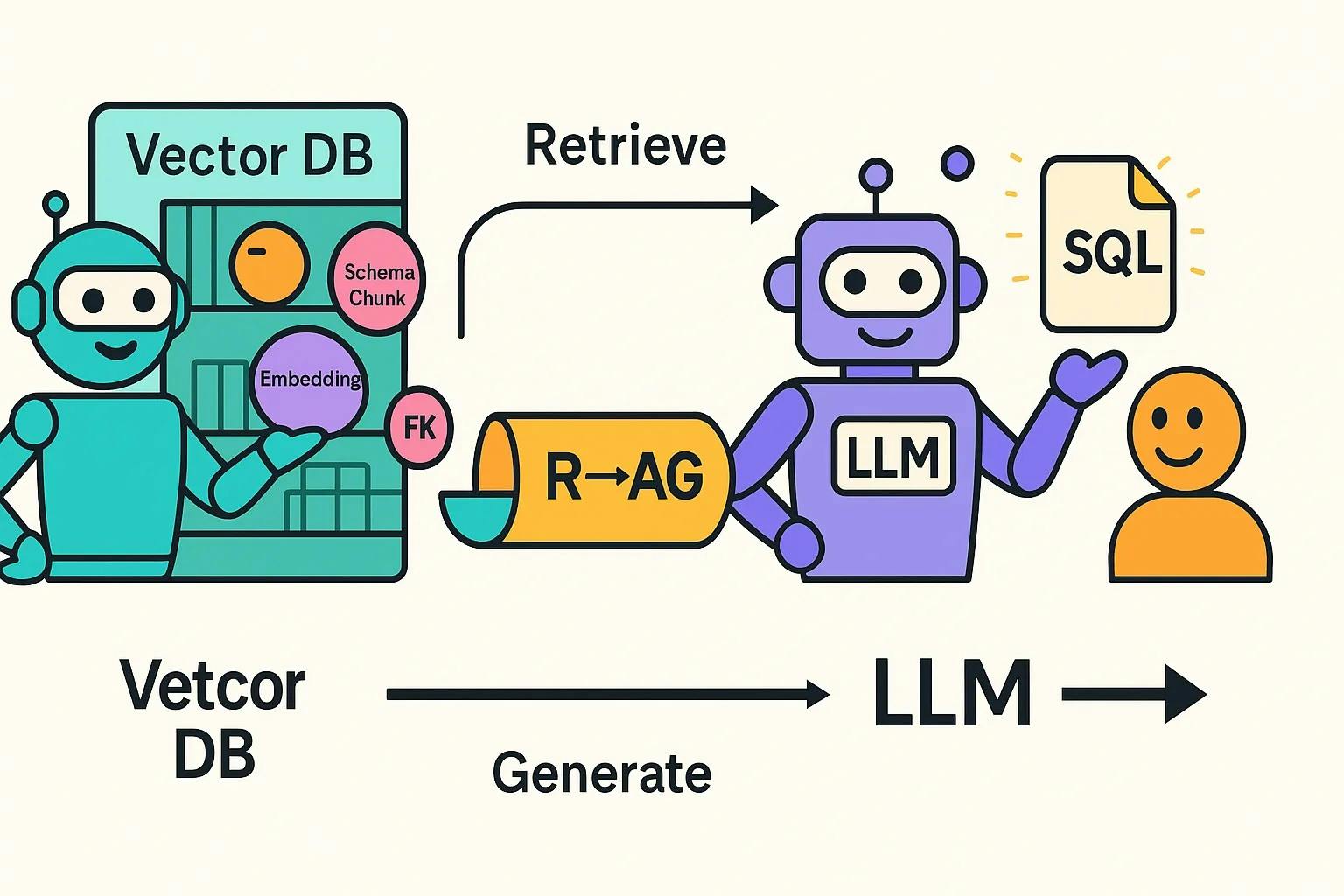
The second part of this project integrates a RAG layer to enhance a LangChain-MySQL agent, addressing speed issues and OpenAI rate limits. By harnessing a persistent FAISS vector store, important schema elements like keys and indexes are selectively loaded, streamlining prompts and improving response times. The implementation incorporates a comprehensive test suite to catch schema drifts and retrieval inaccuracies. Furthermore, foreign key relationships have been introduced to enrich schema representation and cut down on token usage, resolving previous major challenges of lost table relationships and excessive schema bulk in prompts.
"Contextualizing database schemas into a vector format reduces the complexity for LLM-based retrieval while simultaneously addressing the common rate limit issues with OpenAI APIs."
"Leveraging persistent FAISS vector stores enables more efficient and targeted querying that minimizes token consumption, leading to faster responses from the LLM."
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]