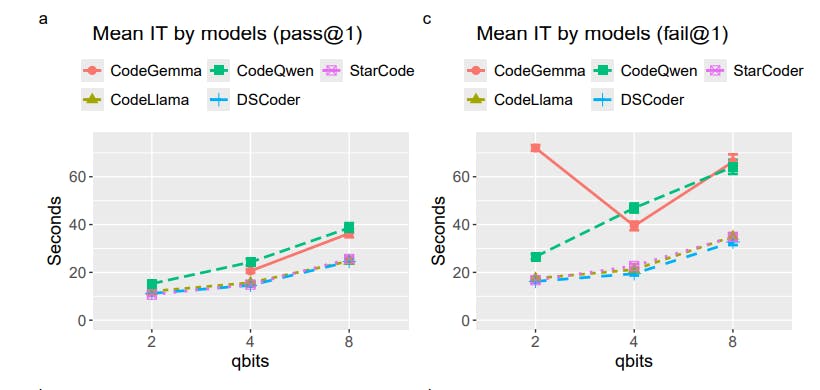
"For all models, the inference time increased with higher precision (more qbits), with failed solutions taking significantly longer than correct ones."
"CodeQwen showed variable inference performance across benchmarks, where longer inference times did not always correlate with better results, especially at lower precision."
The article discusses the inference times of various coding models—CodeGemma, StarCoder, DeepSeek Coder, and CodeQwen—analyzing how performance relates to precision measured in qubits. It reveals that models generally experienced increased inference times with higher precision, particularly for incorrect solutions. CodeQwen, while performing well at 8-bit precision, did not leverage longer inference times effectively at lower precision levels. Notably, CodeGemma exhibited prolonged inference times without correspondingly better results, especially at 2-bit quantization where its inference ability faltered, indicating that longer times don't always correlate with improved performance in machine learning models.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]