Data science
fromInfoQ
1 day agoGoogle's TurboQuant Compression May Support Faster Inference, Same Accuracy on Less Capable Hardware
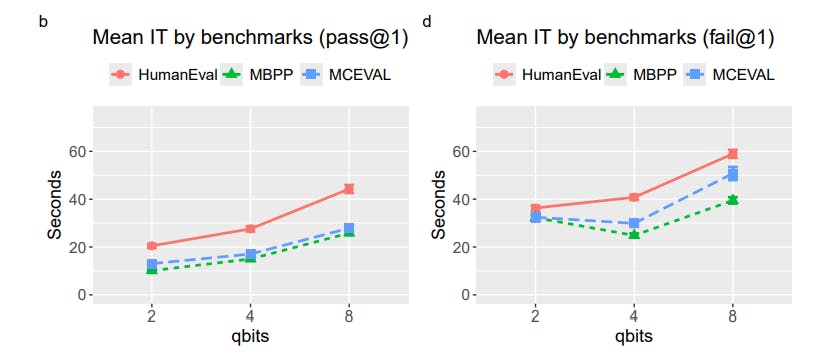
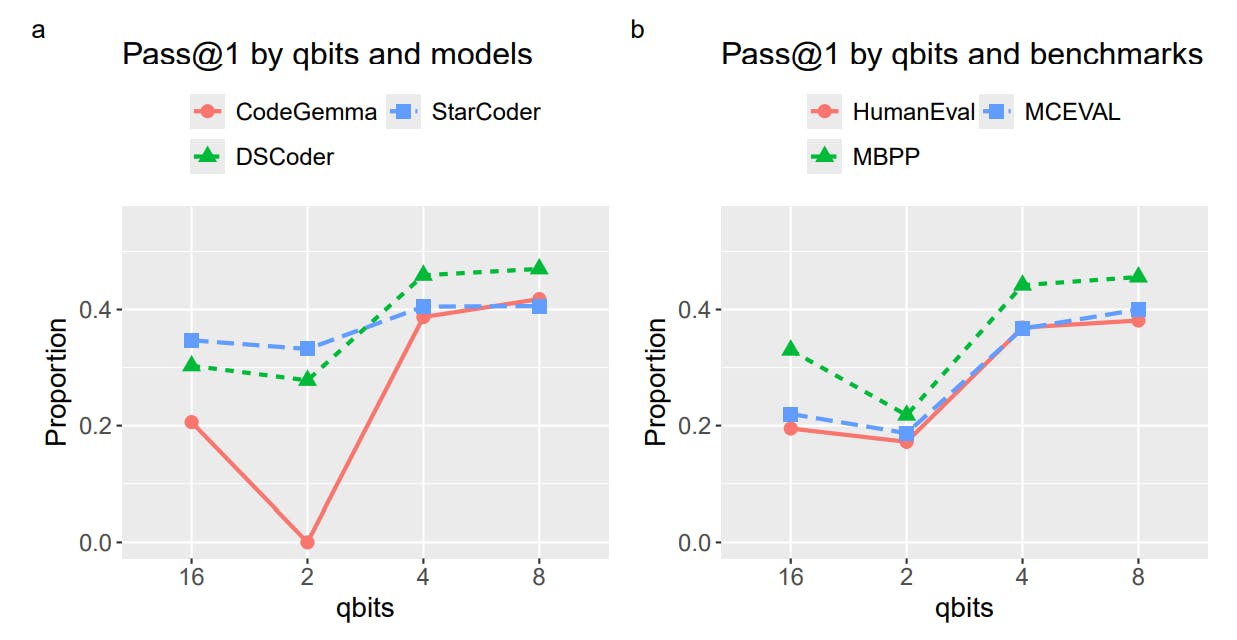
TurboQuant compresses language models' Key-Value caches by up to 6x with near-zero accuracy loss, enabling efficient use of modest hardware.