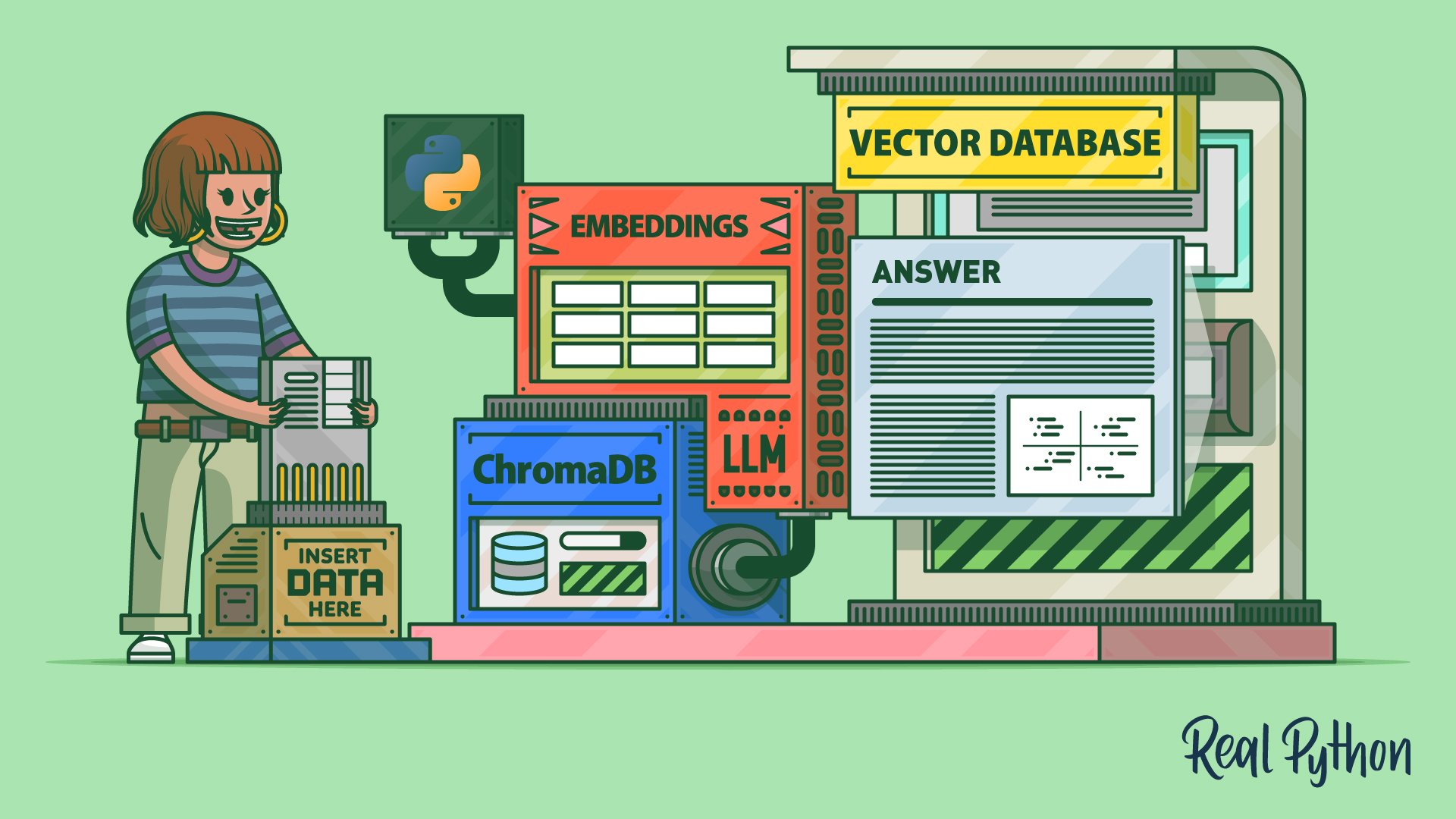
Large language models (LLMs) are transforming applications with their ability to process natural language. However, they have limitations, such as the inability to access information outside their training data and token count restrictions. To enhance LLM applications, vector databases like ChromaDB can be utilized. These databases store unstructured data as vectors, enabling efficient querying and retrieval of relevant documents. A course is available to teach users how to represent unstructured objects, use embeddings in Python, and leverage ChromaDB for improved context in LLMs.
"Modern LLMs, while imperfect, can accurately solve a wide range of problems and provide correct answers to many questions. However, due to the limits of their training and the number of text tokens they can process, LLMs aren't a silver bullet for all tasks."
"To address these limitations and scale your LLM applications, a great option is to use a vector database like ChromaDB. A vector database allows you to store encoded unstructured objects, like text, as lists of numbers that can be compared to one another."
"After watching, you'll have the foundational knowledge to use ChromaDB in your NLP or LLM applications. Before watching, you should be comfortable with the basics of Python and high school math."
Read at Realpython
Unable to calculate read time
Collection
[
|
...
]