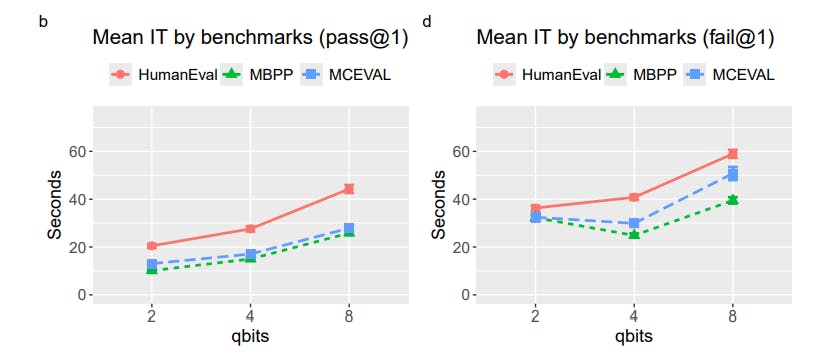
"The increase in inference time in higher precision models is mainly due to longer forward pass time rather than longer output generation time. Higher precision models take longer to compute."
"Correct solutions in HumanEval require more lines of code than benchmarks like MBPP and MCEVAL. Interestingly, MBPP requires slightly more lines than MCEVAL but has less inference time."
"Instead of using quantized models, it may be advantageous to use non-quantized models with a smaller number of parameters, as demonstrated in the study comparing FP16 models."
"The low-parameter FP16 models performed roughly at the level of 2-bit quantized models, suggesting that less complexity may yield comparable performance."
The article explores the efficacy of different coding models with varying precision levels, revealing that higher quantization does not improve the number of lines of code generated. While increased precision leads to longer inference times, this does not enhance performance across models like CodeQwen and CodeGemma. Additionally, a comparison of half-precision (FP16) models indicates that lower-parameter non-quantized models can be as efficient as their quantized counterparts, presenting a viable alternative in coding solution performance.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]