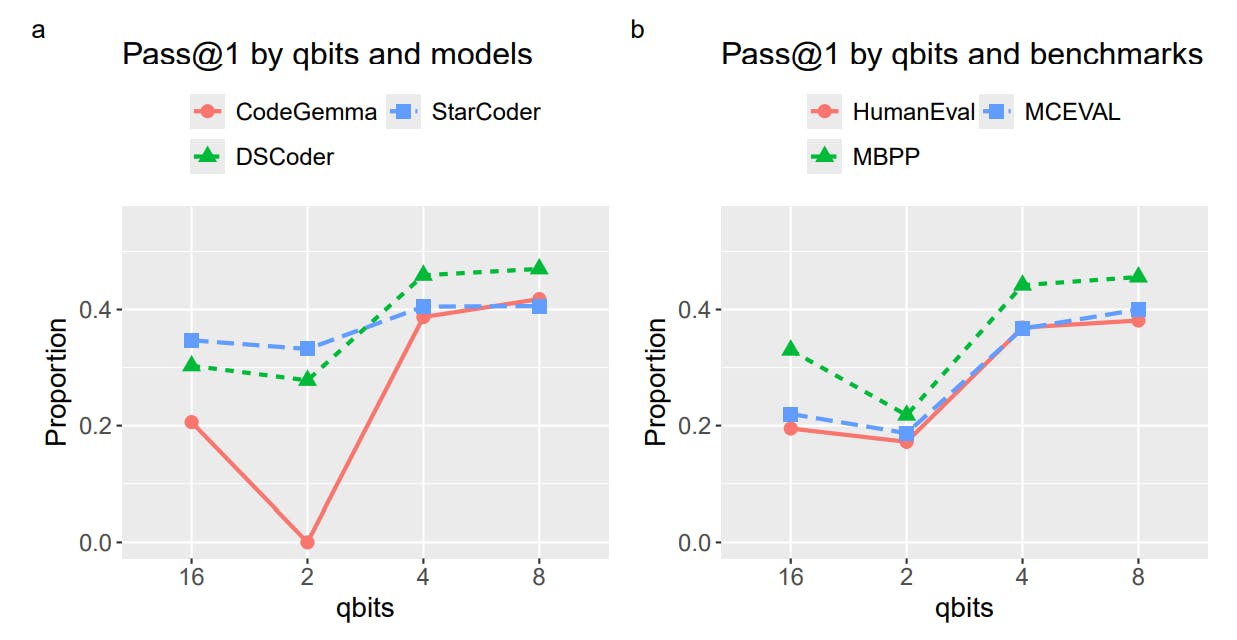
"The results suggest that 4-bit integer quantization provides the best balance between model performance and size, outperforming half-precision models despite having fewer parameters."
"In extreme cases, 2-bit integer quantization led to a complete breakdown in model coherence, illustrating the significant impacts of low precision rounding on token prediction."
The article discusses the effectiveness of 4-bit integer quantization, which offers an optimal blend of performance and size for models. Notably, 7 billion parameter quantized models achieved better results than larger half-precision models. In contrast, 2-bit quantization resulted in severe performance issues, including a total failure to generate coherent responses. Additionally, it highlights advancement in LLM training techniques that likely contribute to better performance metrics in newer models, despite being lower in parameters compared to earlier benchmarks from different studies.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]