Psychology
fromwww.theguardian.com
4 days agoHow to train your brain to see possibility instead of doom
Humility and the ability to tolerate uncertainty are essential cognitive skills in a world filled with unpredictability.
About one in seven couples in the UK will have difficulty conceiving, and about one in eight known pregnancies will end in a loss. As many as 29% of low-risk pregnancies will experience unforeseen complications.
You just finished a design project. And it was a mess. Timelines constantly shifted. Stakeholders disagreed, going back and forth. You made calls without enough data to support them. Maybe the final design wasn't what you wanted. Now comes the hard part: thinking about how you're going to talk about it in your portfolio or case study. Most designers have one basic instinct in this scenario: clean it up. Tell the story as if there was no conflict, no missteps, and a smooth experience.
Last week, I caught myself starting The Office for what must be the fifteenth time. My partner walked in, saw Jim pranking Dwight with the stapler in Jell-O, and just shook his head. "Again?" he asked. And honestly? I couldn't explain why I kept going back to the same show when there's literally endless content available at my fingertips. But here's the thing: I'm not alone in this.
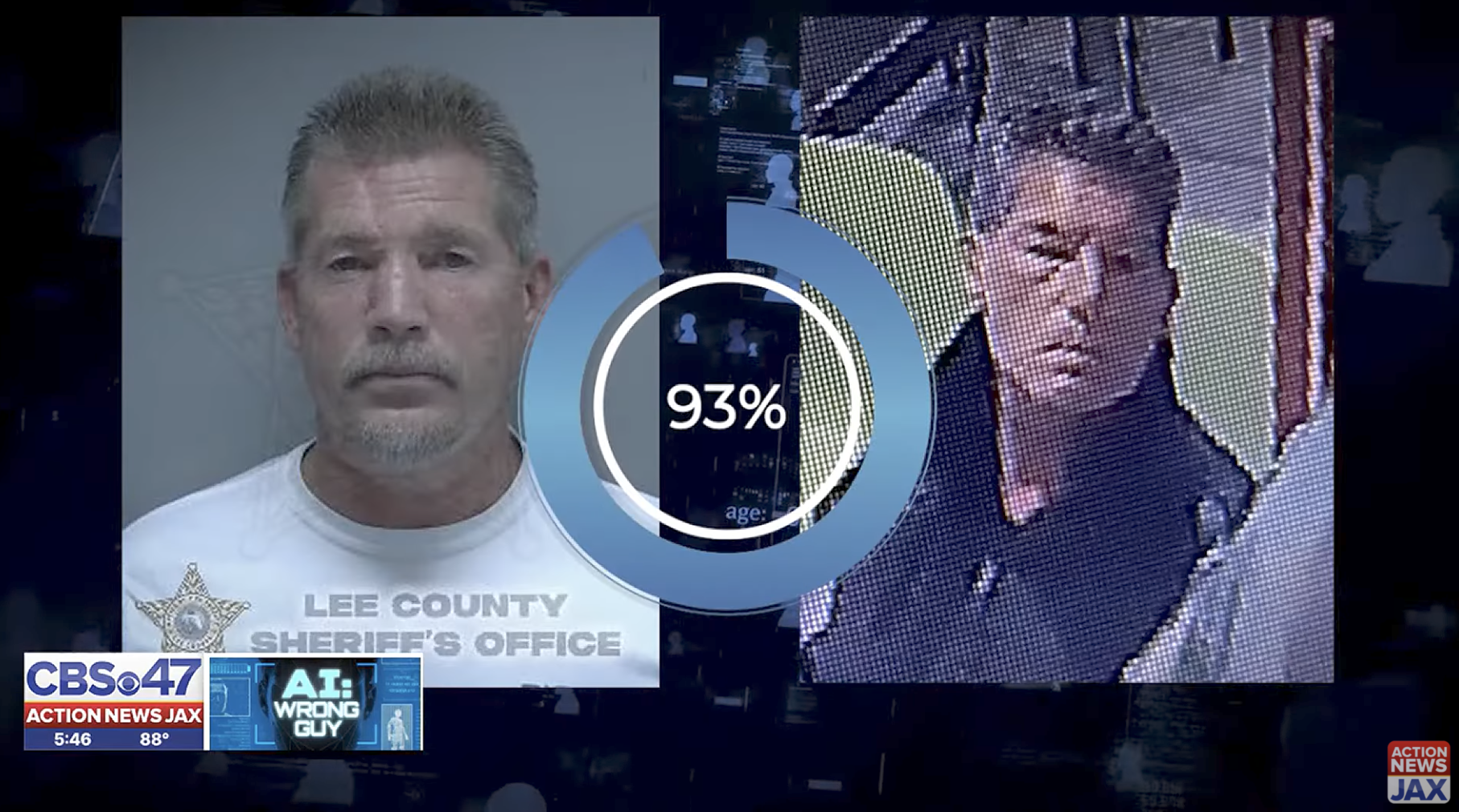
One of the strangest things about large language models is not what they get wrong, but what they assume to be correct. LLMs behave as if every question already has an answer. It's as if reality itself is always a kind of crossword puzzle. The clues may be hard, the grid may be vast and complex, but the solution is presumed to exist. Somewhere, just waiting to be filled in.
The red sphere, originally associated with the ritual of celebration and the expectation of magic, is stripped of its function and returned to the landscape as a heavy, vulnerable form without foundation. Suspended by a hemp rope from a bare century-old tree, the object exists between ground and space; neither in fall nor at rest, but in a prolonged state of uncertainty.
At the start of a new year, it's human nature to want a crystal ball: What lies ahead, and how will it affect us? This feeling is particularly acute in times of uncertainty, when the ability to engage in meaningful foresight can feel elusive at best. And whether the world is objectively more volatile, it certainly feels that way to CEOs: Based on our analysis of earnings calls, 2025 saw a significant spike in discussions about uncertainty, with little sign of abating in 2026.
Everybody knows this coworker-the one who spirals about cost-cutting layoffs when snacks vanish from the break room. The one who thinks they're getting fired because their boss hasn't been using emojis with them lately. The one who's the office Chicken Little: anxious, somewhat frantic, often misguided . . . and who can't stop talking to others about whatever it is they're anxious about.
You've seen it all on your social media feed: people working from the beach, at a roadside hut, or on a train to another city, every day a different adventure. Digital nomads are rewriting what the typical nine-to-five looks like, and more than ever, you're convinced that it's the right path for you, too. After all, if remote work has become so normalized, why not take advantage of it? But the digital nomad lifestyle, glamorous as it may seem, might not be for everyone.
In making an idea together, you are trying to build a shared reality. We are both building a non-existent thing. Because improvisers are creating something out of nothing, they are forced to listen to each other, to pay attention, in a deeper way than in their ordinary lives. People can make assumptions and skim over details in their day-to-day lives, but while improvising, they have to catch every word and even catch details that go beyond their partner's words.
The authors have retracted this paper for the following reasons: post-publication, the results were found to be sensitive to the removal of one country, Uzbekistan, where inaccuracies were noted in the underlying economic data for the period 19951999. Furthermore, spatial auto-correlation was argued to be relevant for the uncertainty ranges. The authors corrected the data from Uzbekistan for 19951999 and controlled for data source transitions and higher-order trends as present in the Uzbekistan data.
The figure of the witch has always been tied to the gift of seeing the future: the three witches from Macbeth, the powerful volvas (Viking witches), Galadriel the elf in Lord of the Rings, all endowed with a special intuition which in a society that is turning to esotericism on social media to deal with great uncertainty, as evidenced by accounts like @charcastrology and @horoscoponegro it is possible to start thinking you may have these powers as well.
If we want to build a better life, we have to be able to not know. Does that sound confusing? Perhaps you don't know what I'm talking about? Good! That's great practice. If you cannot tolerate not knowing, you run the risk of arranging your life so you can know everything (or at least try to), and you may end up sapping your existence of any spontaneity and joy.
The answer requires what I call wisdom of temporal perspectives in our decision-making. The wisdom of temporal perspectives involves the temporal appraisal of the current situation, where we take into consideration past factors that give rise to the situation and future consequences that may transpire when solving problems and making decisions. It is a form of transformational wisdom that is particularly important in a complex world of challenges today.
For example, clowns are not supposed to be scary. They are funny-singing, dancing, joke-telling jesters. But, if we change the context of the clown and their purpose, then it's reasonable to understand why they're scary. My dislike predates the horror movie IT (1990), which is said to represent a landmark increase in coulrophobia ( fear of clowns) cases. I remember being around three or four
Writing a business contract is like predicting the future. It's a series of if/then statements - if this happens, then such-and-such party is responsible for that. The idea is that neither side really trusts the other. So a contract, backed up by the highest legal authority, gives a company something that it can put its trust in. That's why a firm's lawyers include every little thing they can think of.
What might this be? Well, I don't have a complete answer. But I am convinced that the foundation is developing the ability to live with intention. Intention is nothing other than the ability to make free and conscious choices, and when we are able to do this consistently, we become the authors of our own stories, protagonists who co-create the world rather than being determined by it.
The main argument here is that spiritual strength is fundamentally about cultivating wisdom. From a psychological perspective, spirituality isn't about dogma or belief; it is about developing the kind of wisdom necessary to face suffering without denial, accept uncertainty without despair, and discover meaning beyond the ego. Modern cognitive scientists, such as John Vervaeke, describe wisdom in two dimensions: moral (what serves the greater good, the long view) and cognitive (navigating complexity, managing strong emotions, and distinguishing the essential from the trivial).
The admission came in a paper [PDF] published in early September, titled "Why Language Models Hallucinate," and penned by three OpenAI researchers and Santosh Vempala, a distinguished professor of computer science at Georgia Institute of Technology. It concludes that "the majority of mainstream evaluations reward hallucinatory behavior." Language models are primarily evaluated using exams that penalize uncertainty. The fundamental problem is that AI models are trained to reward guesswork, rather than the correct answer.
You feel like you've been on a roller coaster, constantly applying for jobs and searching for the perfect one. You've sent an updated resume and cover letter. You answered all the questions. You were asked to submit video answers to questions. And now you wait. Will you be called for an interview? After the tenth time of checking your email, the uncertainty in your head starts to take over, leading you to question yourself: "Why did I even try? I'm not as good as the other applicants. What makes me think they'd want me?"